Error Handling & Retry with Apache Beam and Flink
March 26, 2022
This guide discusses one of the approaches to retry errors when running Apache Beam applications with Apache Flink. While the approach discussed here could be applied to any Beam pipeline in general, decide and settle on an error handling strategy that suits your use case.
Apache Beam pipeline may throw exceptions while processing data. Some of these errors are transient (e.g., temporary difficulty accessing an external service), but some are permanent, such as errors caused by corrupt or unparseable input data.
Error Types
- Non-Transient Errors (Permanent)
- Transient Errors (Temporary)
The diagram below illustrates a sample pipeline that reads data from an input stream, does some transformations, and writes data back to a data sink. Transient errors are handled using a checkpoint-based restart strategy, while a dead letter queue approach is used to handle non-transient errors.
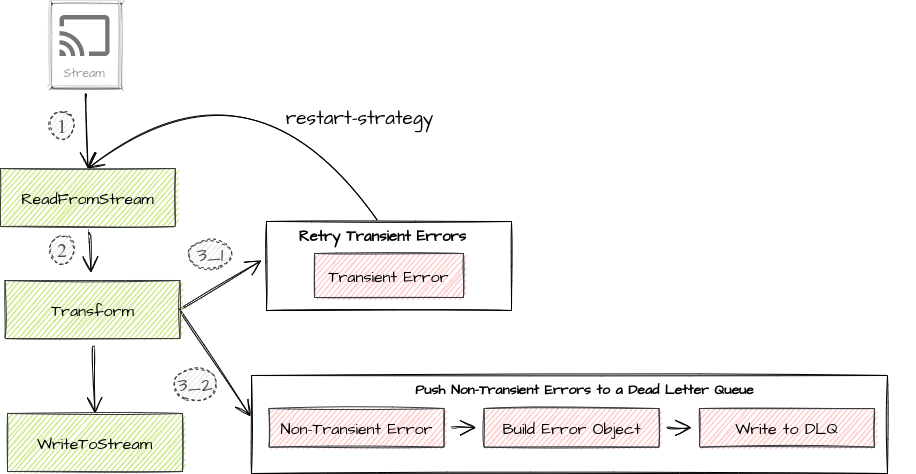
Since a non-transient error will continue to occur as long as it is not corrected, there’s no point in retrying such errors. Beam’s DoFn instances process elements in arbitrary bundles. If an exception is thrown for any element in the bundle and it is not caught, it’ll cause the Flink job to be restarted. Flink runner then has to recreate the operators. The states of these operators will be restored from the last successful checkpoint. For example, the read offset of the recovered source operator will then have a safe offset to restart from. When running in streaming mode, unless a retry threshold is set, a bundle including a failing item will be retried indefinitely, which may cause the pipeline to permanently stall. So it is a must to catch all non-transient errors.
Handling Non-Transient Errors
Handling with a TupleTag
In this approach, exceptions caused due to non-transient errors should be caught within the DoFn.ProcessElement method. And we’d log the errors as we normally would. But instead of dropping the failed element, branch the outputs to write failed elements into a separate PCollection object as follows.
void processElement(ProcessContext c) {
try {
c.output(objectMapper.writeValueAsString(c.element()));
} catch (Exception e) {
LOG.severe("Failed due to non-transient error {} - adding to dead letter queue", c.element(), e);
c.sideOutput(deadLetterTupleTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
These elements can then be written to a database, or a message queue for later inspection, by using another transform.
outputPCollectionTupple.get(deadLetterTag)
.apply(new WriteToDeadLetterQueue());
Handling with Beam’s WithFailure
WithFailure is a type of exception handler provided by Beam for writing transforms that can handle exceptions raised during the processing of elements. The exception handler would receive an object of type WithFailures.ExceptionElement as the input along with the original input element that was being processed when the exception was raised. WithFailure may not be suitable for transforms that may throw both transient, and non-transient errors. Since it would catch every type of exception, we won’t be able to utilize Flink’s retry capabilities even to retry transient errors.
Transient Errors (Temporary)
The DoFn’s may fail due to transient errors such as temporary outages, or exceptions thrown due to external service failures. Instead of catching such exceptions (dead letter queue approach), we could let Flink retry such failed operations.
When a failure happens, Flink needs to restart the failed task and other affected tasks to recover the job to a normal state. Restart strategies and failover strategies are used to control the task restarting.
When checkpointing is enabled Flink would recover the state from the last successful checkpoint. By default ‘fixed-delay’ restart strategy is used for streaming jobs, with infinite retries every 10 seconds.
The following pipeline options are provided by the Flink runner, which you could pass as program arguements to enable checkpointing and to adjust the application’s retry behavior.
| # | Option | Description |
|---|---|---|
| 1 | --checkpointingInterval | Checkpointing interval in milliseconds |
| 2 | --executionRetryDelay | Delay in milliseconds between retires |
| 3 | --numberOfExecutionRetries | You may use a larger value if you've coded your app to retry only for transient errors. So the pipeline could eventually recover itself once the underlying error go away |
Differentiate Between Transient & Non-Transient Errors
An error could be identified as a transient or non-transient error based on the Java type of the exception being thrown. Unless the exception is known to be due to a transient error (an error that could eventually recover by retrying), that exception should be considered as a non-transient error.
class CustomDoFn<I, O> extends DoFn<I, O> {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
try {
process(c);
} catch (Exception e) {
handleException(e);
}
}
protected void handleException(Exception e) throws Exception {
Throwable cause = ExceptionUtil.getRootCause(e);
if (cause instanceof TransientErrorException || ..)
throw e;
}
protected abstract void process(DoFn<I, O>.ProcessContext c) throws Exception;
}
To eliminate the need to write exception handling logic in every user-defined DoFn, you may define a CustomDoFn class that your other DoFn classes could inherit from.
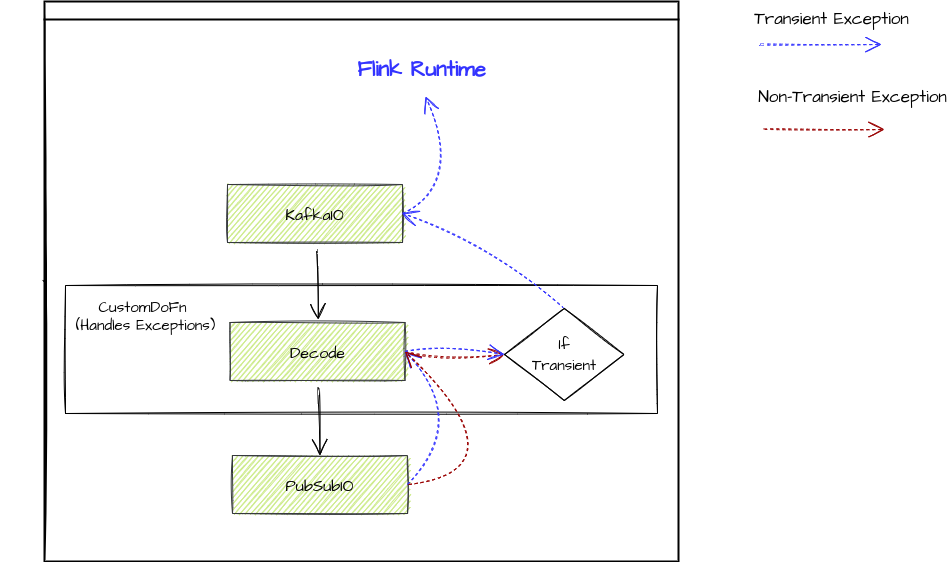
How Exceptions Propagate
The following diagram shows how exceptions propagate in Apache Beam. Since transient exceptions are not caught, those exceptions will cause Flink’s restart strategy to kick in.
Recovery and Retry Behavior
When a task failure happens, Flink restarts the failed task and other affected tasks. The last successful checkpoint is then used to recover the state including the corresponding stream positions.
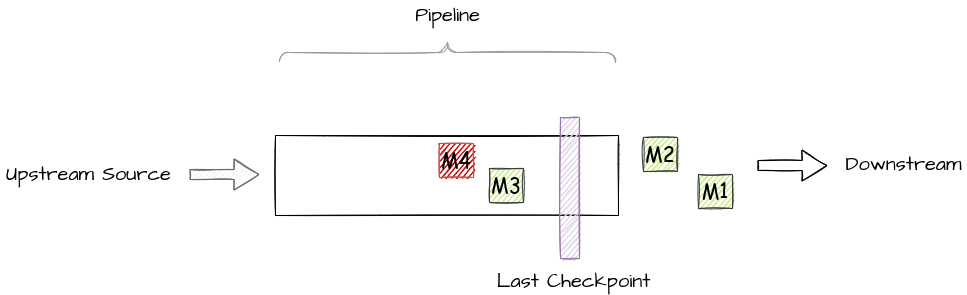
Assume a scenario where the pipeline consumed four messages, M1, M2, M3, and M4. M1 and M2 were already sunk downstream. M3 and M4 are currently in processing.
When PubsubIO is being used as the source operator, message acknowledgment happens at the time of checkpoint finalization. So in the above example, only M1, and M2 are acknowledged. Say the pipeline fails to process M4 due to a transient error, this would cause related tasks to be restarted starting from the last successful checkpoint. So M3 and M4 will be replayed, starting from the source operator.
If the source operator is a KafkaIO for example, when the task restarts, the operator state will be recovered with properties such as the latest offset consumed so far, that are stored in the last successful checkpoint.